


内容摘要:本报告概述了人工智能语言模型的基本情况,根据经合组织“人工智能系统分类框架”,从人与地球、经济背景、数据与输入、人工智能语言模型、任务与输出等5个维度,深入阐述了人工智能语言模型的进化生态系统根据,最后根据2019年经合组织的“人工智能原则”,从5个方面提出了其主张的价值观原则,并提出了5项政策建议。报告认为,自然语言处理技术近年来发展迅速、应用广泛,给人类经济社会发展带来了诸多益处。但生成式人工智能技术和大型语言模型的开发和部署,也带来了道德、环境、安全等方面的多样化挑战。对此,应着眼造福人类和地球,坚持以人为核心,关注模型的透明度、可解释性、安全性、稳妥性等问题,强化问责,从研发投资、数字生态系统建设、形成有利政策环境、促进劳动力转型、广泛开展合作等方面,确保可信人工智能语言模型的开发、部署和正确使用。
人工智能语言模型概况
自然语言处理是人工智能的一个子集,它是指通过分析、生成、修改或响应人类文本和语音来实现自然语言功能自动化的计算机程序和工具。它使用语言作为输入,也产出语言作为输出,或者二者兼而有之。语言模型是自然语言处理研究的核心,是通常采用了机器学习技术的语言领域的模型。聊天机器人、机器翻译系统、语音识别虚拟助手等,均是使用语言模型的应用程序。各国政府已认识到,在加强公共服务、推广本国语言、提高生产力、降低成本等方面,人工智能语言模型和其他自然语言处理应用的重要性日益增长。经合组织国家及其伙伴经济体均提出了各自的国家行动计划和战略,以鼓励或指导本国语言的自然语言处理系统开发与部署。
根据自然语言处理开源数据库Hugging Face的资源显示,在数字语言资源中,英语占比38%,其次是西班牙语、德语和法语,汉语数据虽然据称很多,但在该数据库中较少(图1)。由于英语以外语言的人工智能训练数据可得性较低,这一领域的关键趋势是投资开发非英语的数字语言资源,包括不太常用的语言或土著语言。此外,依托私营部门、学术界和民间社团组成的合作伙伴网络,形成了多个自然语言处理研究中心和协作平台。越来越多的跨国界倡议也倡导分享专门知识和最佳实践,促进各国语言数据系统的互操作性。
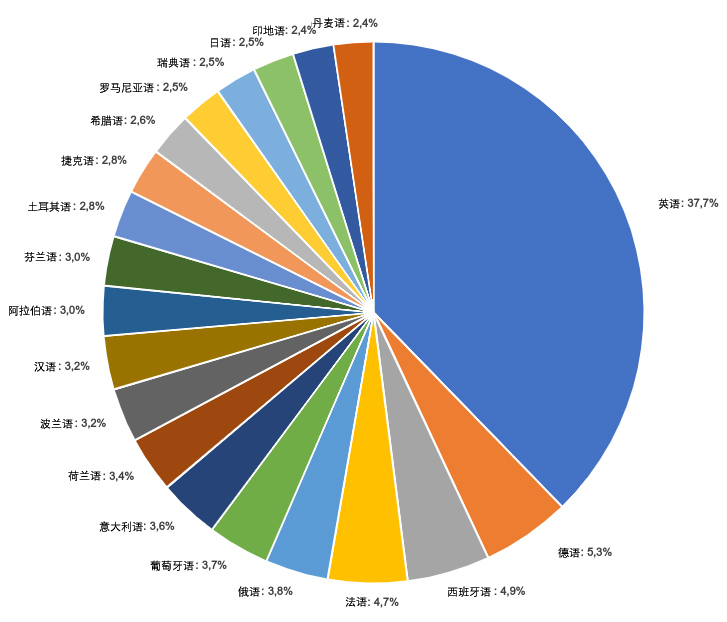
图1 2023年Hugging Face中按语种分类的人工智能数据集(排名前20的语种)
对人工智能语言模型的5个维度考察
经合组织“人工智能系统分类框架”提出了人与地球、经济背景、数据与输入、人工智能模型、任务与输出5个维度,借此可深入理解人工智能语言模型的进化生态系统。
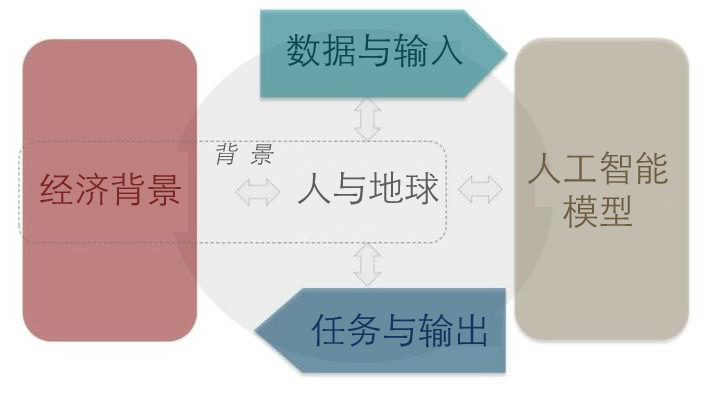
图2 经合组织“人工智能系统分类框架”的5个维度
2.1人与地球
现有许多语言资源和模型都是英语的,因此倾向于英语使用者。其中的工人和消费者是主要影响对象,因为人工智能语言模型可能导致翻译、问答等任务的自动化。此外,无法接触人工智能语言模型的人也深受影响,因为他们得不到这些系统所带来的经济利益和机会。
2.2经济背景
大型科技公司正在大规模研究、设计和部署通用的自然语言处理系统,并将其应用于公共管理、医疗保健、法律、零售等诸多领域。语言模型尤其是大型人工智能语言模型产生了巨大且持续增长的经济影响力,因为语言是人类交流的主要载体,语言技能可以增强跨文化技能和全球合作,带来新的创新思维方式和跨文化工作方式,从而为个人和社会带来经济效益。
2.3数据与输入
语言模型的数据与输入包括语言资源(含书面和口头语料库)、语法和术语数据库、标注语料库、人工反馈等。对于开发和部署可信的人工智能语言模型而言,数据的选择和管理至关重要。选择数据时,应当考虑数据的代表性、准确性、可靠性,同时评估其中是否包含私人信息或偏见;对选定的数据集进行管理,就是要标记和清理不一致的数据,并在必要时删除个人信息和偏见。
2.4人工智能语言模型
人工智能语言模型迄今为止最接近于生成式人工智能,它们可以处理大量的自然语言输入并生成自然语言输出、甚至是视觉输出。它们通常以参数数量、层与准确性为特征。“参数”是指模型通过对特定任务的训练而独立改变的值;“层”指的是输入序列处理或迭代的不同阶段。其中,参数数量是人工智能语言模型研究的核心。
2.5任务与输出
自然语言处理包含命名实体识别、词性标注、文本分类、句法分析、机器翻译等5项任务。它可分为自然语言理解和自然语言生成2个子类:前者是将自然语言输入转换成机器可理解的形式,主要有关系抽取、语义分析、问题回答、情感分析、文本摘要等任务;后者指的是自然语言的产生,主要有语篇生成、词汇选择、句子生成、文档结构等。另一个相关概念是自动语音识别,主要有语言加权、说话人标签、声学训练、脏话过滤等4项内容。
政策考虑
根据2019年经合组织“人工智能原则”,提出以下五项基于价值观的原则和五项政策建议。
3.1造福人类和地球(原则1.1)
人工智能语言模型在许多环境和行业中对包容性增长、可持续发展和福祉产生着积极影响。它们部署在公共管理、医疗保健、银行、法律等多个行业,完成了诸多需要大规模运用人类自然语言的任务,释放出巨大的社会和经济机会。
3.2透明度和可解释性(原则1.3)
目前大多数人工智能语言模型依赖于神经网络。这是一项复杂、深奥的高级统计建模技术,即使是开发者也常常不理解其作用原理,因此被称为“黑箱”。这是对语言模型透明度和可解释性的核心挑战。
透明度包括公布使用语言模型的时机、提供正确使用指导、发现滥用警告等。这些是涉及语言模型开发和使用的重要且有意义的信息。可解释性指的是使受影响人群理解其产生机理,并向其提供易于理解的信息,使受到负面影响的人能够挑战结果。一般来说,模型越复杂,就越难以解释。
此外,还有以人为核心的价值观和公平性(原则1.2)、鲁棒性、安全性和稳妥性(原则1.4)、问责(原则1.5)、投资研发(原则2.1)、建立数字生态系统(原则2.2)、促进有力的政策环境(原则2.3)、建设人类能力,为劳动力转型做好准备(原则2.4)、开展国际、跨学科和多利益相关者的合作(原则2.5)。
发布时间|2023年4月
文章来源|经合组织
原文标题|AI Language Models: Technological, Socio-Economic and Policy Considerations
原文地址|https://read.oecd.org/10.1787/13d38f92-en?format=pdf(52页)
Last modified: 2023年 5月 25日




